In simple terms, a RAG system first retrieves relevant information from your data, then augments the LLM's context with that information, and finally generates a response grounded in real, verifiable facts rather than potentially outdated training data. This combination of retrieval and generation is why Retrieval-Augmented Generation has become the go-to architecture for enterprise AI applications, intelligent search, legal research tools, medical assistants, and much more.
This guide covers everything you need to understand RAG from the ground up: what it is, why it works, how the pipeline operates step by step, the most popular RAG architectures used in production today, and the real-world use cases where RAG delivers the most value.
1. What Exactly is RAG (Retrieval-Augmented Generation)?
RAG (Retrieval-Augmented Generation) is an AI framework that enhances the output of a large language model by supplying it with relevant, up-to-date context retrieved from an external knowledge source — before the model generates its final response. The term was coined in a landmark 2020 paper by Facebook AI Research (Meta), and it has since become one of the most widely adopted patterns in applied AI.
To understand why RAG matters, you first need to understand the core problem it solves. A standard LLM — whether GPT-4, Claude, or Gemini — is trained on a snapshot of data up to a certain date. After training, it has no ability to update itself. If you ask it about a law that changed last month, a product released last week, or a policy in your internal HR handbook, it will either make something up (a phenomenon called "hallucination") or simply say it does not know.
RAG breaks this limitation by giving the LLM a "cheat sheet" at query time. Instead of relying purely on memorized knowledge, the LLM is shown the most relevant passages from a knowledge base — your documents, your database, your website — and told to base its answer on those passages. The result is a response that is both fluent and factually grounded, with the ability to cite specific sources.
Think of it this way: a standard LLM is like a brilliant expert who read millions of books three years ago and cannot access anything since. A RAG-powered LLM is like that same expert, but now sitting next to a research assistant who can instantly pull the most relevant pages from any library in the world before the expert speaks.
RAG vs Fine-Tuning: What is the Difference?
Many developers ask whether they should use RAG or fine-tune an LLM for their specific domain. These are fundamentally different approaches. Fine-tuning bakes knowledge into the model's weights during a new training run — it is expensive, slow, and requires a large, high-quality labelled dataset. More importantly, fine-tuned knowledge becomes stale just as quickly as the original training data.
RAG, on the other hand, keeps the knowledge external and updatable. You can add a new document to your knowledge base and the RAG system immediately has access to it — no retraining required. For most real-world applications where data changes frequently, RAG is the more practical, cost-effective, and flexible choice. The two approaches are not mutually exclusive either: you can fine-tune a model for style and tone, then use RAG to provide it with current factual knowledge.
Key Components of a RAG System
Every RAG system is built on three foundational components working together in sequence:
- Retriever: The component responsible for searching the knowledge base and fetching the most relevant pieces of information for a given query. It converts both the query and the stored documents into mathematical representations (embeddings) and finds the closest matches using similarity search.
- Knowledge Base (Vector Store): The external data repository — typically a vector database — that stores all your documents as numerical vectors. Common options include Pinecone, Weaviate, Chroma, FAISS, and Qdrant.
- Generator (LLM): The large language model that receives the user's original question plus the retrieved context and generates a coherent, grounded final answer. This can be GPT-4o, Claude 3, Llama 3, Mistral, or any capable LLM.
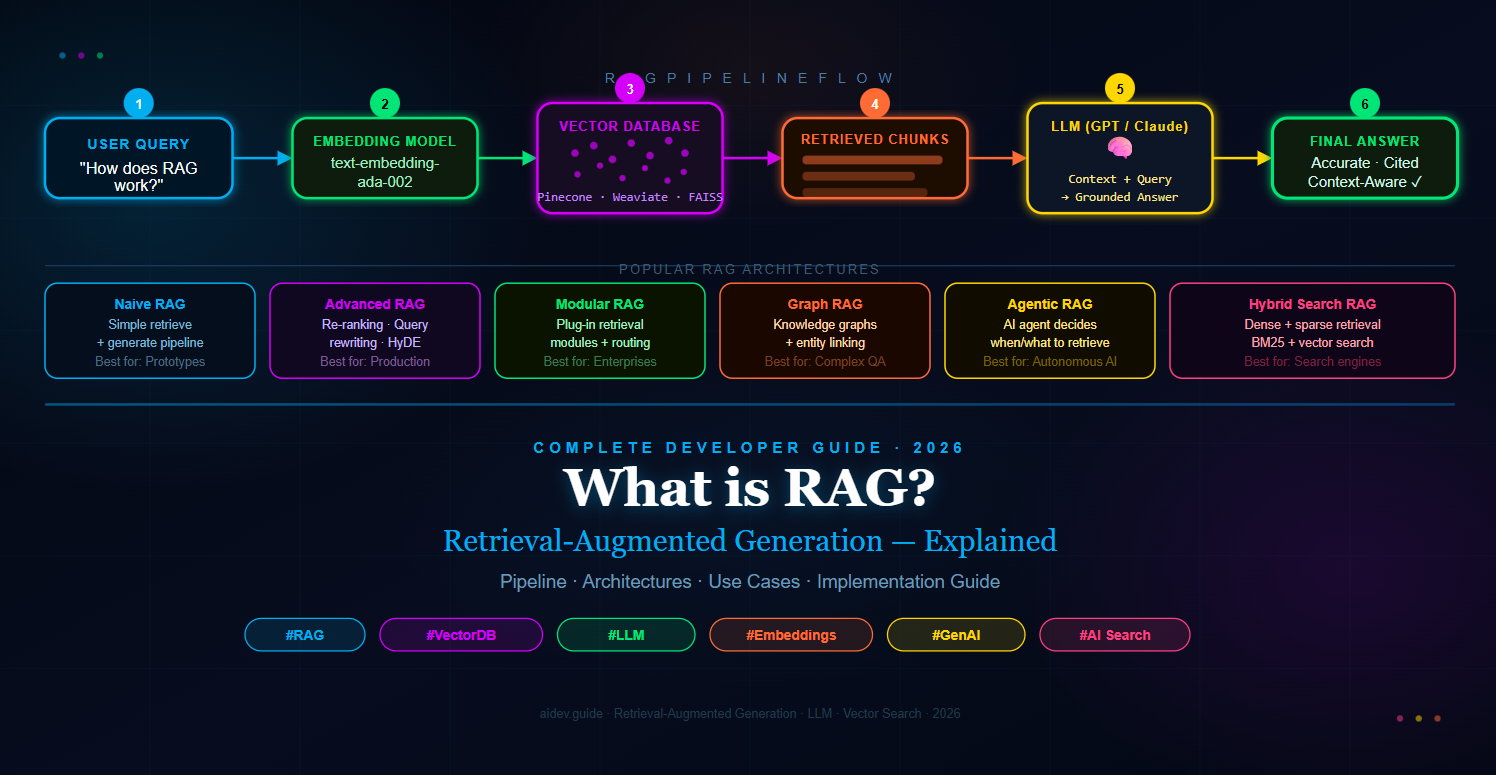
These three components — retrieve, augment, generate — work in a tight sequence every time a user submits a query. Understanding this sequence in detail is the key to mastering RAG Retrieval-Augmented Generation architecture.
2. Why is RAG So Popular?
The explosive popularity of RAG (Retrieval-Augmented Generation) is not an accident. It addresses a precise set of pain points that have frustrated AI practitioners since the earliest days of deploying LLMs in production. Understanding these pain points explains exactly why RAG has become the dominant architecture for knowledge-intensive AI applications.
It Eliminates Hallucinations
LLM hallucination — where the model confidently states something completely false — is the single biggest barrier to enterprise AI adoption. In high-stakes domains like legal, medical, or financial applications, a wrong answer is not just unhelpful, it is dangerous. RAG dramatically reduces hallucination by grounding every response in retrieved source documents. When the LLM is told "answer based only on the following context," it has no need to fabricate information. If the answer is not in the retrieved passages, a well-prompted RAG system will say so rather than invent one.
Knowledge Stays Fresh Without Retraining
Fine-tuning an LLM to update its knowledge costs thousands of dollars in compute, takes days, and still results in a model with a new fixed cutoff date. RAG sidesteps this entirely. Your knowledge base is a live database. Add a document today, and your RAG system can cite it tonight. For companies that deal with rapidly changing information — regulatory updates, product catalogs, news feeds, clinical trials — this freshness is not a nice-to-have, it is a business requirement.
It is Transparent and Auditable
Because RAG retrieves specific source passages before generating a response, it is straightforward to show users exactly where the answer came from. This source attribution is critical in regulated industries. A legal AI tool that says "according to Section 4.2 of Contract #X-2024" is far more trustworthy than one that just provides an answer with no provenance. RAG makes AI decisions explainable and auditable in a way that pure LLM generation cannot.
It Works With Private, Internal Data
Public LLMs are trained on internet data. They know nothing about your company's proprietary documentation, your internal wikis, your CRM records, or your support ticket history. RAG is the standard solution for building AI applications on top of private data without sending that data to a model training pipeline. You keep your data in your vector database, behind your firewall, and the LLM only sees the specific passages needed to answer each query.
Cost Efficiency at Scale
Sending an entire document to an LLM as context is expensive and slow. Most LLMs charge per token, and context windows — even large ones — have limits. RAG solves this by retrieving only the two to five most relevant passages from potentially millions of documents. The LLM receives a small, targeted context window, which reduces cost per query and keeps response latency low even on large knowledge bases.
3. The Entire RAG Pipeline — Step by Step
The RAG pipeline has two distinct phases: an offline indexing phase that you run once (or periodically) to prepare your knowledge base, and an online inference phase that runs in real time every time a user submits a query. Understanding both phases in detail is essential for building reliable RAG systems.
Phase 1: Indexing (Offline)
The indexing phase is where you ingest all your source documents and convert them into a form that can be efficiently searched. This phase typically runs once at setup and then incrementally as new documents are added. It involves four key steps.
Step 1 — Load and Parse Documents
The first step is ingesting your raw data from whatever format it lives in. Documents might be PDFs, Word files, Markdown files, web pages, database records, JSON exports, or plain text. Each data source requires a dedicated loader that extracts clean, readable text from the raw file format.
Libraries like LangChain and LlamaIndex provide ready-made loaders for dozens of document types. The output of this step is a collection of raw text strings — one per document or document section.
Step 2 — Chunk the Documents
Most documents are too long to be retrieved as a single unit. A 200-page PDF cannot be sent to an LLM as a single chunk — it would exceed the context window and contain far more information than is relevant to any single query. The solution is chunking: splitting each document into smaller overlapping segments of roughly 200–1000 tokens each.
The chunking strategy significantly impacts retrieval quality. Chunks that are too small lose context; chunks that are too large retrieve irrelevant information alongside the useful content. Overlapping chunks (where consecutive chunks share 10–20% of their tokens) help prevent important information from falling between chunk boundaries. Advanced RAG systems use semantic chunking — splitting at natural topic boundaries rather than fixed token counts — to produce more coherent retrieval units.
Step 3 — Generate Embeddings
Once your documents are chunked, each chunk is passed through an embedding model — a neural network that converts text into a dense numerical vector (typically 768 to 3072 dimensions). This vector is a mathematical fingerprint of the chunk's semantic meaning. Texts with similar meanings will have vectors that are geometrically close to each other in this high-dimensional space, even if they use completely different words.
Popular embedding models include OpenAI's text-embedding-3-large, Cohere's Embed v3, Google's text-embedding-004, and open-source options like sentence-transformers/all-MiniLM-L6-v2. The choice of embedding model is one of the most consequential decisions in RAG system design — it determines the quality of semantic search.
Step 4 — Store in a Vector Database
The final step of the indexing phase is storing each chunk's text and its embedding vector in a vector database. A vector database is purpose-built to perform fast approximate nearest-neighbour (ANN) search across millions of high-dimensional vectors. When you later search for chunks similar to a query, the vector database can find the top K most similar vectors in milliseconds.
Popular vector databases include:
- Pinecone — Fully managed, highly scalable, production-grade cloud vector database
- Weaviate — Open-source, supports hybrid search (dense + sparse), self-hostable
- Chroma — Open-source, lightweight, ideal for local development and small projects
- FAISS — Facebook AI Similarity Search, a C++ library for in-memory vector search
- Qdrant — Open-source, Rust-based, excellent performance and filtering capabilities
- pgvector — PostgreSQL extension that adds vector search to your existing SQL database
Each chunk is stored alongside its metadata — the source document name, page number, section heading, author, date, and any other attributes useful for filtering or citation.
Phase 2: Inference (Real-Time, Per Query)
The inference phase is what happens every time a user submits a question. It is a real-time pipeline that must complete in under two to three seconds for a good user experience. It involves four steps that mirror the indexing phase.
Step 5 — Embed the User Query
When a user types a question, it is immediately passed through the same embedding model used during indexing. This produces a query vector in the same dimensional space as the stored document vectors, making semantic comparison mathematically valid. Using the same embedding model for both documents and queries is critical — mismatched models produce meaningless similarity scores.
Step 6 — Retrieve the Top-K Relevant Chunks
The query vector is submitted to the vector database, which performs a similarity search — typically using cosine similarity or dot product — and returns the top K most semantically similar chunks. K is usually between 3 and 10, chosen based on how much context the LLM can usefully process and how much token cost is acceptable per query.
In advanced RAG systems, this retrieval step may also include a re-ranking stage where a dedicated cross-encoder model (such as Cohere Rerank or BGE Reranker) scores each retrieved chunk against the query and reorders them by relevance. Re-ranking significantly improves retrieval precision and is one of the highest-ROI improvements you can make to a RAG system.
Step 7 — Augment the Prompt
The retrieved chunks are assembled into a structured prompt that is sent to the LLM. This prompt contains the user's original question and the retrieved context, wrapped in clear instructions. The system prompt typically tells the model to answer based only on the provided context, to cite its sources, and to say "I don't know" if the answer is not in the context.
A typical augmented prompt looks like this:
System: You are a helpful assistant. Answer the user's question using ONLY
the context provided below. If the answer is not in the context,
say "I don't have enough information to answer that."
Always cite the source document name at the end of your answer.
Context:
[CHUNK 1 — Source: company-handbook.pdf, Page 12]
All employees are entitled to 25 days of annual leave per year...
[CHUNK 2 — Source: hr-policy-2025.pdf, Page 3]
Leave requests must be submitted at least 14 days in advance...
[CHUNK 3 — Source: benefits-guide.pdf, Page 7]
Unused leave up to 10 days may be carried over to the following year...
User Question: How much annual leave do I get and can I carry it over?
Step 8 — Generate the Final Answer
The augmented prompt is sent to the LLM via API. The model reads the context, synthesises the relevant information, and generates a coherent, grounded response. Because the answer is based on real retrieved passages rather than memorised training data, it is accurate, current, and traceable to a source. The response is returned to the user, typically with source citations displayed alongside it.
4. Most Popular RAG Architectures
As RAG Retrieval-Augmented Generation has matured from a research concept into a production engineering discipline, several distinct architectural patterns have emerged. Each addresses specific limitations of simpler approaches and is suited to different use cases, data complexities, and performance requirements. Knowing which architecture to choose is the difference between a RAG system that works well in a demo and one that reliably serves millions of queries.
Naive RAG (Basic RAG)
Naive RAG is the simplest implementation: chunk documents, embed chunks, store in a vector database, retrieve top-K on query, and pass retrieved chunks plus the query to the LLM. This pattern is excellent for proof-of-concept projects, internal tools with a small knowledge base, and domains where simple keyword-level semantic similarity is sufficient.
The limitation of Naive RAG is that its retrieval quality is directly limited by the quality of the embedding similarity. If the user's query is phrased very differently from the way the answer is written in the source document, semantic search may miss the relevant chunk entirely. It also has no mechanism for handling complex multi-part questions or queries that require combining information from multiple unrelated documents.
Advanced RAG
Advanced RAG addresses Naive RAG's retrieval limitations with a set of pre-retrieval and post-retrieval enhancements. These techniques are now considered standard practice for production RAG systems. The most impactful improvements include:
- Query Rewriting: Before retrieval, an LLM rephrases the user's query into a form more likely to match the vocabulary used in the source documents. This bridges the "vocabulary gap" between how users ask questions and how experts write documentation.
- HyDE (Hypothetical Document Embeddings): Instead of embedding the raw query, the system first generates a hypothetical answer using the LLM, then embeds that hypothetical answer. Since hypothetical answers tend to be semantically closer to real document passages, retrieval accuracy improves significantly.
- Re-ranking: After initial retrieval, a dedicated cross-encoder model scores each chunk against the query for precise relevance and reorders the results. This two-stage retrieve-then-rerank pattern consistently outperforms single-stage retrieval.
- Contextual Compression: Retrieved chunks often contain a mix of relevant and irrelevant sentences. Contextual compression extracts only the sentences within each chunk that directly answer the query, reducing noise in the LLM context window.
Advanced RAG is the recommended starting architecture for any customer-facing or business-critical RAG application. The additional retrieval steps add 200–500ms of latency but typically produce a 20–40% improvement in answer quality metrics.
Modular RAG
Modular RAG treats the retrieval pipeline as a set of interchangeable, composable modules rather than a fixed sequence. Each module — document loader, chunker, embedder, retriever, re-ranker, compressor, generator — is a standalone component with a defined interface. Different modules can be swapped, combined, or parallelised depending on the query type.
A Modular RAG system might route simple factual queries through a fast, lightweight retrieval path while routing complex analytical queries through a more expensive multi-step retrieval and reasoning pipeline. This architecture is particularly valuable for enterprises with diverse data sources (SQL databases, PDFs, APIs, email archives) that require different retrieval strategies for each source type.
Graph RAG
Graph RAG augments standard vector search with a knowledge graph — a structured representation of entities (people, places, concepts, products) and the relationships between them. While vector search excels at finding semantically similar text passages, it struggles with relational queries: "Who are the direct reports of the VP of Engineering?" or "Which clinical trials involved patients with both diabetes and hypertension?"
In Graph RAG, documents are first processed to extract entities and relationships, which are stored in a graph database (Neo4j, Amazon Neptune). At query time, the system determines whether the query is relational or semantic and routes it accordingly — or combines both graph traversal and vector search for maximum coverage. Microsoft's GraphRAG implementation, released in 2024, demonstrated dramatically better performance on multi-hop reasoning tasks compared to standard vector-only RAG.
Agentic RAG
Agentic RAG moves beyond fixed, sequential pipelines by giving an AI agent the autonomy to decide how to retrieve information based on the complexity and nature of each query. The agent can choose to search the vector database, query a SQL database, call an external API, browse the web, or combine multiple retrieval strategies — then reason about whether the retrieved information is sufficient or whether it needs to retrieve more before generating an answer.
This architecture is best suited for tasks that require genuine multi-step reasoning — research assistants that need to gather information from multiple sources, analytical tools that combine database queries with document search, or customer service agents that need to check order status via API while simultaneously consulting a product knowledge base. Agentic RAG trades simplicity and predictability for dramatically greater capability.
Hybrid Search RAG
Hybrid Search RAG combines two complementary retrieval methods: dense vector search (which excels at semantic similarity) and sparse keyword search (which excels at exact term matching). The most common sparse retrieval algorithm is BM25, a battle-tested information retrieval algorithm used in traditional search engines. By fusing the scores from both methods using a technique called Reciprocal Rank Fusion (RRF), Hybrid RAG achieves better recall than either method alone.
This architecture is particularly valuable for knowledge bases that contain a mix of natural language documents and technical content with precise terminology — part numbers, medical codes, legal citations — where exact keyword matching is as important as semantic understanding. Most modern vector databases, including Weaviate, Elasticsearch, and Qdrant, support hybrid search natively.
5. RAG Use Cases
RAG Retrieval-Augmented Generation is not a solution looking for a problem — it addresses specific, high-value scenarios where the combination of LLM language capability and precise retrieval delivers results that neither technology could achieve alone. Here are the most impactful real-world use cases where RAG is being deployed at scale today.
Enterprise Knowledge Management and Internal Search
Large organisations accumulate enormous amounts of institutional knowledge in wikis, SharePoint sites, Confluence pages, Slack archives, email threads, and PDF manuals — most of which is never efficiently utilised because it is too difficult to search. RAG transforms this unstructured knowledge into an intelligent assistant that employees can query in plain English: "What is our policy on contractor NDAs?" or "How do I set up the dev environment for the payments service?" instead of spending 20 minutes searching through documentation.
Companies deploying internal RAG systems consistently report 30–50% reductions in time spent searching for information and significant improvements in onboarding speed for new employees. Unlike a public chatbot, the internal knowledge base stays entirely within the company's infrastructure — RAG works with your data, not OpenAI's training set.
Customer Support and Intelligent Helpdesk
RAG is the backbone of modern AI customer support systems. The knowledge base contains product documentation, FAQs, troubleshooting guides, return policies, and past resolved support tickets. When a customer asks a question, the RAG system retrieves the most relevant support articles and generates a precise, accurate answer — rather than a generic response that forces the customer to read an entire help article.
The quality advantage over standard chatbots is substantial. A RAG-powered support bot can answer questions about firmware version 3.2.1 of a product released last month because the product documentation was added to the knowledge base at release — no model retraining required. It can also escalate appropriately when the retrieved context does not contain an answer, rather than hallucinating a resolution.
Legal and Compliance Research
Legal professionals spend an enormous proportion of their working hours reviewing case law, statutes, regulations, and contracts to find relevant precedents or compliance requirements. RAG systems indexed on legal databases (legislation, court rulings, regulatory guidance) allow lawyers and compliance officers to ask natural language questions and receive cited, source-attributed answers in seconds rather than hours.
The citation and source attribution features of RAG are particularly critical in legal contexts — a RAG system that answers "this claim is supported by Smith v. Jones (2019) at paragraph 42" is providing genuine legal research value, not just a plausible-sounding summary. Law firms like Allen & Overy and Harvey AI have deployed RAG-based tools that measurably reduce research time for junior associates.
Medical and Clinical Decision Support
In healthcare, RAG systems can be trained on clinical guidelines, drug interaction databases, medical literature (PubMed, Cochrane reviews), and patient history records to support clinical decision-making. A physician can query "what are the first-line treatment options for treatment-resistant depression in a patient with comorbid hypertension?" and receive a response grounded in the latest clinical guidelines, with citations, rather than an answer based on potentially outdated training data.
The ability to keep the knowledge base current without model retraining is especially valuable in medicine, where clinical guidelines are updated regularly as new evidence emerges. RAG systems also support explainability requirements in medical AI — because the answer is grounded in retrieved documents, the reasoning chain is inherently auditable.
Financial Research and Investment Analysis
Financial analysts use RAG to query large corpora of earnings call transcripts, analyst reports, SEC filings, and market research reports. Instead of manually reviewing hundreds of documents, an analyst can ask "what did Apple's CEO say about AI investment plans in the last three earnings calls?" and receive a synthesised answer with exact quotes and source attribution from the relevant transcripts.
RAG systems in finance can also be connected to real-time data feeds — news wires, earnings releases, regulatory filings — ensuring that the knowledge base reflects the current market environment rather than a training cutoff from six months ago. This combination of real-time data access and LLM synthesis is a genuinely transformative capability for investment research workflows.
Education and Personalised Tutoring
Educational RAG applications allow students to have natural language conversations with their course materials. A student studying constitutional law can ask their AI tutor "can you explain the holding in Marbury v. Madison and how it relates to what we covered in Chapter 3?" The RAG system retrieves the relevant passages from the textbook and course notes and generates an explanation tailored to the student's curriculum — not a generic Wikipedia summary.
Publishers and EdTech platforms are deploying RAG to allow students to interact directly with their licensed textbooks, producing contextually relevant explanations, practice questions, and summaries from the actual content the student is studying. This represents a fundamentally better use of LLM capabilities than generic tutoring, which often drifts away from curriculum-specific content.
Code and Developer Documentation Assistant
Developer tools like GitHub Copilot, Sourcegraph Cody, and AWS Q Developer use RAG to retrieve relevant code snippets, API documentation, and repository context before generating code suggestions. When a developer asks "how do I implement pagination in our Django REST Framework API?", the RAG system retrieves the project's existing API patterns, the team's coding conventions, and the relevant DRF documentation before generating a suggestion that actually fits the existing codebase — rather than a generic example.
This use case illustrates one of RAG's most powerful properties: the ability to personalise LLM output to a specific organisation's context, conventions, and existing code, rather than producing generic output trained on public GitHub repositories.
How to Get Started with RAG
If you are ready to build your first RAG Retrieval-Augmented Generation system, the ecosystem of tools available in 2026 makes the process remarkably accessible. You do not need to build retrieval infrastructure from scratch — the following frameworks and services handle most of the complexity.
- LangChain — The most widely used RAG framework for Python and JavaScript. Provides abstractions for document loaders, text splitters, embedding models, vector stores, and retrieval chains. Excellent for rapid prototyping and production deployment alike.
- LlamaIndex — Purpose-built for data ingestion and RAG. Particularly strong for complex indexing scenarios involving multiple data sources and advanced retrieval patterns. Preferred by many teams for production RAG over LangChain due to its more opinionated, structured approach.
- Haystack (deepset) — An open-source NLP framework with excellent RAG pipeline support, strong typing, and good documentation. Particularly popular in European enterprise contexts.
- Semantic Kernel (Microsoft) — Microsoft's SDK for integrating LLMs and RAG into .NET and Python applications. Tightly integrated with Azure OpenAI and Azure Cognitive Search.
- Vercel AI SDK / Mastra — TypeScript-first options for JavaScript developers building RAG-powered web applications.
For vector databases, start with Chroma for local development (it runs entirely in memory with no setup required) and migrate to Pinecone or Weaviate for production deployments that require scalability, persistence, and multi-tenant support.
For embedding models, OpenAI's text-embedding-3-small is an excellent starting point — it is fast, affordable, and consistently outperforms older embedding models. For privacy-sensitive applications where you cannot send data to external APIs, sentence-transformers/all-MiniLM-L6-v2 or BAAI/bge-large-en-v1.5 are strong open-source alternatives that can run entirely on your own infrastructure.
Common Challenges and How to Solve Them
Building a RAG system that performs well in a demo is straightforward. Building one that reliably performs well in production is considerably harder. Here are the most common failure modes in RAG systems and the proven strategies for addressing each one.
Poor retrieval quality is the most common root cause of bad RAG performance. If the wrong chunks are retrieved, even the best LLM will generate a poor answer. Fixes include: improving chunking strategy, upgrading the embedding model, adding query rewriting, and implementing re-ranking. Evaluate retrieval quality independently from generation quality using metrics like Recall@K before debugging the LLM component.
Chunk boundary problems occur when important context is split across chunks. Overlapping chunks (10–20% overlap) and parent-document retrieval (retrieve small chunks for precision, then expand to their parent section for full context) are effective mitigations.
Context window overflow happens when too many chunks are retrieved and the combined context exceeds the LLM's context limit. Reduce K, use contextual compression to extract only the most relevant sentences from each chunk, or upgrade to an LLM with a larger context window (128K+ tokens).
Stale metadata and outdated chunks are a long-term operational concern. Establish clear document lifecycle policies: when a document is updated or deprecated, the corresponding chunks must be removed or updated in the vector store. Without this hygiene, the knowledge base gradually degrades in quality as old information accumulates.
Conclusion
RAG — Retrieval-Augmented Generation — is not just a technical pattern. It is the architectural foundation of the next generation of knowledge-intensive AI applications. By connecting the generative power of large language models to live, searchable, private knowledge bases, RAG makes AI systems that are more accurate, more trustworthy, more transparent, and more practically useful than any pure LLM approach can achieve.
Whether you are building an internal enterprise search tool, a customer support bot, a legal research assistant, or a personalised educational tutor, the same core pattern applies: retrieve the most relevant context, augment the prompt, generate a grounded answer. The sophistication lies in how well you implement each stage of that pipeline — and that is exactly the engineering challenge that the RAG field is solving at remarkable speed.
The six architectures covered in this guide — Naive RAG, Advanced RAG, Modular RAG, Graph RAG, Agentic RAG, and Hybrid Search RAG — represent a spectrum from simple to sophisticated. Start simple, measure retrieval and generation quality rigorously, and add architectural complexity only where the metrics demand it. That disciplined, evidence-driven approach is what separates RAG systems that deliver real business value from those that impress in demos and disappoint in production.